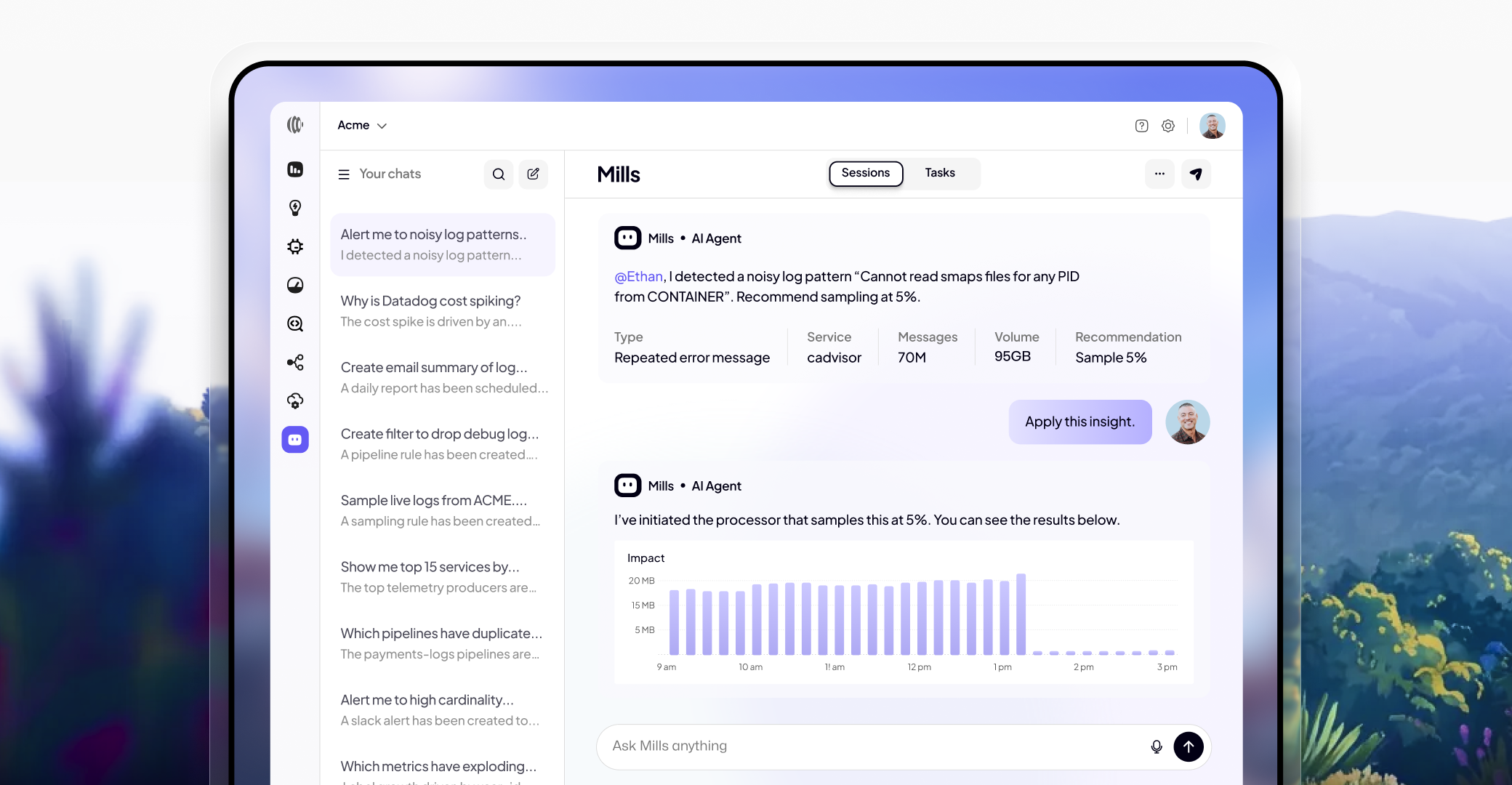
Today, Sawmills is announcing the release of Mills, the world's first agentic telemetry management platform. Mills is an always-on domain expert for your observability stack, built to solve a problem that continues to grow exponentially: telemetry costs are skyrocketing, data quality is declining, visibility is lacking, and engineers are buried under the operational weight of managing it all.
Mills doesn’t just point at problems; it fixes them, running telemetry operations end-to-end and optimizing signals throughout the entire telemetry lifecycle. From code to the CI to production, it continuously optimizes your signals so the data flowing into your observability platform is actually worth paying for.
Most enterprises are paying a fortune for telemetry that's bloated, redundant, and still failing them during incidents," said Ronit Belson, CEO & Co-founder of Sawmills. "Mills fixes that. Developers get the autonomy to manage telemetry end-to-end. DevOps gets the guardrails, quality and control required to ensure telemetry is cost-effective and useful. It's the first time both teams actually win."
Telemetry management across the entire lifecycle
Mills is not a chatbot, a dashboard copilot, or a workflow engine. It's the concertmaster of your telemetry stack. The expert that keeps every instrument in tune, every signal clean, and the whole performance running without missing a beat. It manages telemetry the way a seasoned DevOps engineer would if they could see every pipeline, every service, and every downstream impact simultaneously, around the clock.
And it conducts across the entire telemetry lifecycle, from code and CI pipelines, where it catches problems before they ship, to runtime, where it manages data in-flight and applies fixes, to a feedback loop that routes production insights back into the next development cycle.

What makes Mills different is real domain expertise. It knows what a high-cardinality metric means for your bill, why a log pattern is redundant, when sampling is safe, and when it would destroy the signal you need. It doesn't just flag the off-key notes, it tunes throughout the lifecycle of your telemetry, combining cost and quality analysis, pipeline configuration, and processor management to deliver outcomes rather than isolated fixes. And it gives you full transparency into what it's doing and why, through Slack, Teams, or the Sawmills UI.
The difference between Mills and everything else: "here's a chart of your top cost drivers" versus "I've identified $40K/month in redundant logs, here's the fix. Approve it and I'll deploy."
Developer self-service within DevOps guardrails
Mills is built around how engineering teams actually work. DevOps sets guardrails and policies once. From there, Mills does the rest continuously monitoring your telemetry lifecycle, identifying issues, and delivering a ready-to-apply fix directly to the developer in Slack or Teams. The developer doesn't need to investigate, or build the fix, or even file a ticket. They review the suggestion and approve it. Mills executes the change. Meanwhile, DevOps has full visibility into every suggestion, every approval, and every change, with the ability to roll back instantly.
Imagine this scenario: a developer's service is generating problematic telemetry, like a payment service stuck in a retry loop that's writing the same timeout error to the log millions of times a day. Mills doesn't wait for someone to notice. It alerts the developer directly in Slack or Teams with the issue and a fix like converting a log to a metric, all while keeping the DevOps team in the loop, eliminating the chase and the game of whack-a-mole.
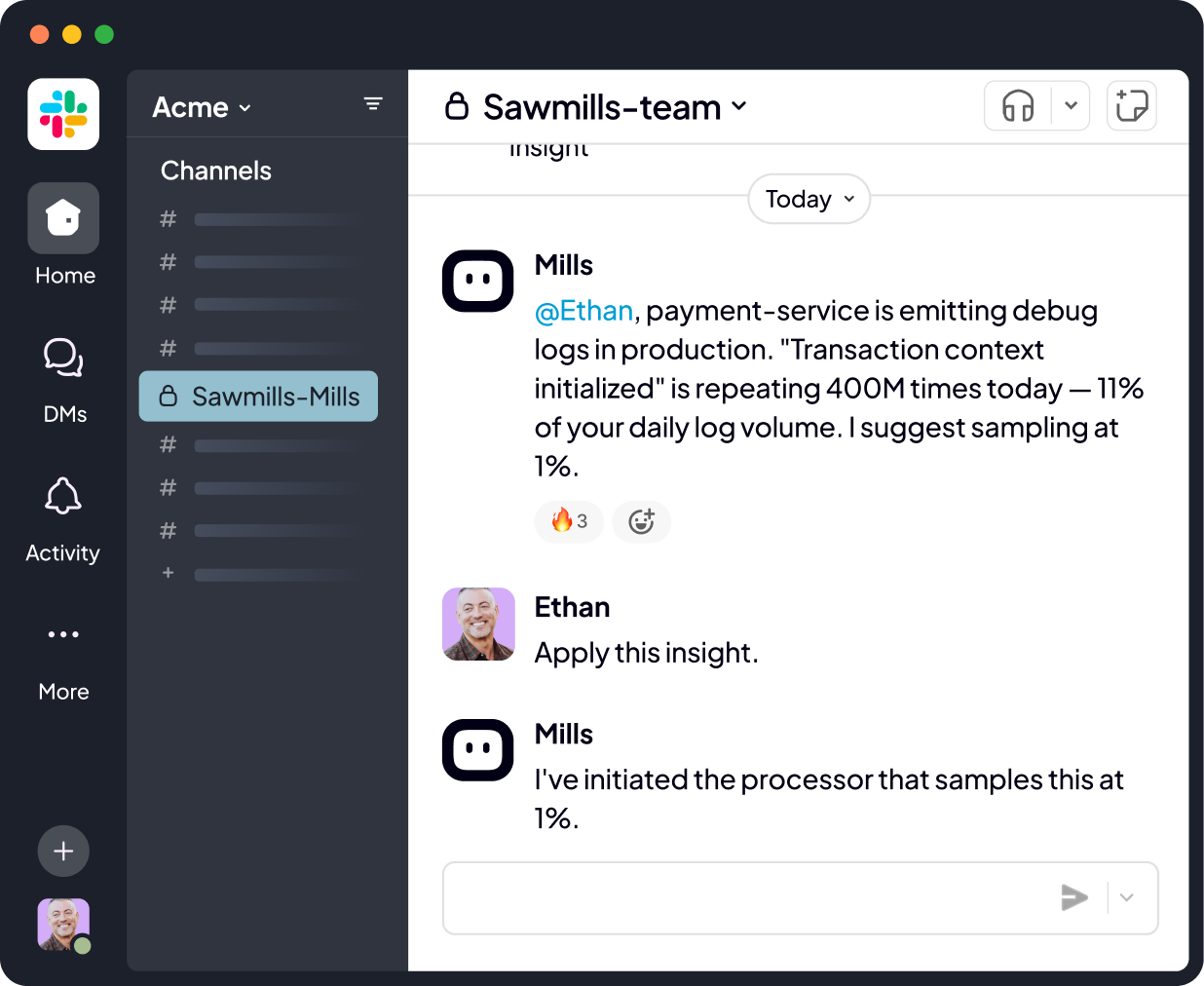
Sawmills customers are already seeing the impact. Measurable cost savings, cleaner data, and observability that actually works. With the Mills release, they're expecting even more.
Day one impact. Every day after.
Mills is the extension of your team that continuously identifies waste, improves data quality, and resolves issues. No platform switch. No ramp-up. You can expect:
- 60–80% reduction in observability costs. Mills identifies the patterns burning budget, things like verbose logs, duplicate entries, high-cardinality metrics, and acts on them automatically or with one-click approval. The savings show up on day one.
- High-value telemetry that delivers signal. Mills transforms data in-flight, converting unstructured logs, deduplicating, enriching, and redacting, so what reaches your backend is clean, structured, and ready to use. Consistent formats across services. Full coverage across your stack. Faster queries. More accurate alerts. Faster root cause analysis..
- No more platform blackouts. Ingestion spikes, exploding cardinality, runaway data, Mills detects and resolves them before they cascade.
- Engineering time back. Issues that once took days of back-and-forth now resolve in minutes through a Slack message. DevOps stops firefighting. Developers stop context-switching.
Telemetry has an operator now.
A year ago, we proved that AI could bring intelligence to telemetry management. Today, with Mills, we're proving that AI can operate it. The telemetry problem was never about better dashboards. It was about having an expert operator that never sleeps, never misses a pattern, and gets smarter with every deploy.
That operator is Mills. The category is agentic telemetry management. And we're just getting started. Get a demo


