

We read Grepr's recent "Sawmills vs Grepr" comparison, and we agree with its starting premise: organizations are drowning in observability data, costs are climbing, and the signal is getting harder to find in the noise. Telemetry pipelines are the answer to that problem.
Where we see things differently is what a pipeline should do for the engineers who depend on it. The Grepr post frames the core distinction as automation versus manual work; their engine decides, ours asks an engineer to review. We think that framing gets the question exactly backwards. The most important thing a telemetry pipeline can give a DevOps or engineering team isn't the removal of decisions. It's control and visibility over the decisions that get made.
Of course, we aren't experts on their product, as they aren't on ours. So we'll explain how we think about the benefits of the Sawmills telemetry pipeline compared to our understanding of Grepr.
How Grepr describes itself
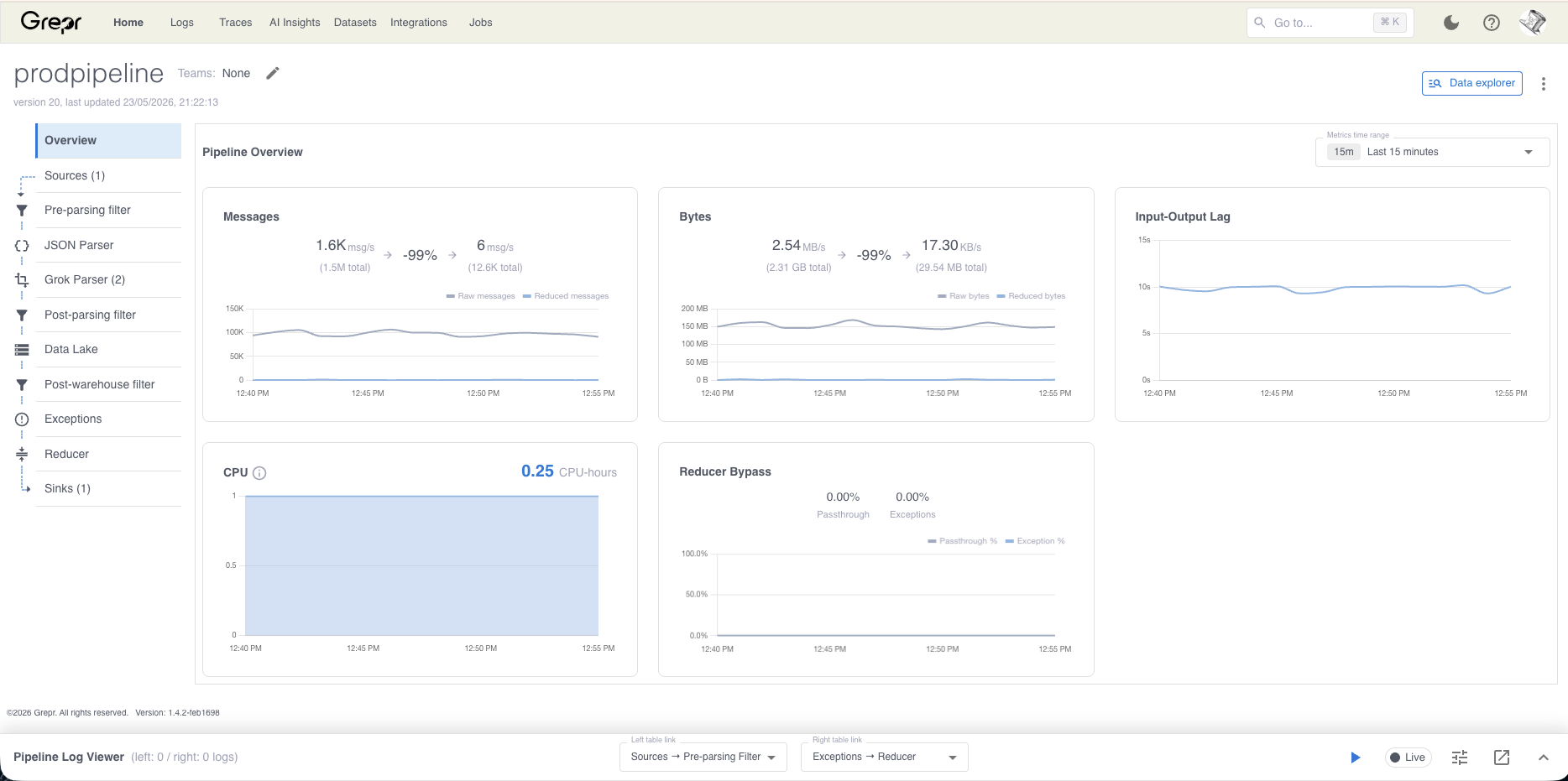
By their own description, Grepr runs on a proprietary pipeline engine rather than an open project like the OpenTelemetry Collector. Logs are sent to Grepr, a machine learning model groups similar messages and aggregates them, and summaries plus a few samples are forwarded to your observability platform while the raw logs sit in an S3 data lake. They describe the reduction as fully automatic: the engine decides what to collapse, and if you want a pattern left alone, you add an exception or wait for an incident-triggered backfill to bring it back. That's the model. Ours starts from a different place.
Why we keep humans in the loop
The Grepr post describes Sawmills as using AI to analyze logs and metrics in stream, surface optimization opportunities such as dropping, sampling, deduplication, and aggregating, and then asking an engineer to approve the recommendation before Sawmills applies it to the pipeline. That's accurate, and it's a deliberate design choice. To understand why, you have to look at who actually owns what in practice.
Here's the split that every observability strategy runs into: DevOps owns the problem, but engineers own the services. DevOps is on the hook for the cost, the noise, and the reliability of the telemetry pipeline. But they don't own the code emitting that telemetry, the engineers do. Those are two different teams with two different mandates, and the data sits right at the seam between them.
This is where a fully automatic, decide-for-you model is challenging in practice. When a machine learning model silently collapses log lines on DevOps's behalf, it's changing what engineers can see about their own services. "Fully automatic" sounds like a benefit until the moment an engineer is mid-incident asking why a particular pattern was summarized away, and the answer is "a model decided that for you."
Sawmills AI analyzes the telemetry in the stream, and allows engineers to see the AI insights. The platform identifies where cost and noise are hiding, shows the specific change it would make, and lets a human make the call on whether Sawmills should apply it to the pipeline or not. We don't see it as manual toil. Rather, it's an informed decision with the analysis already done, and a clear, auditable record of who changed what and why. AI that makes your engineers faster at decisions they stay in charge of is a fundamentally different thing than AI that makes the decisions.
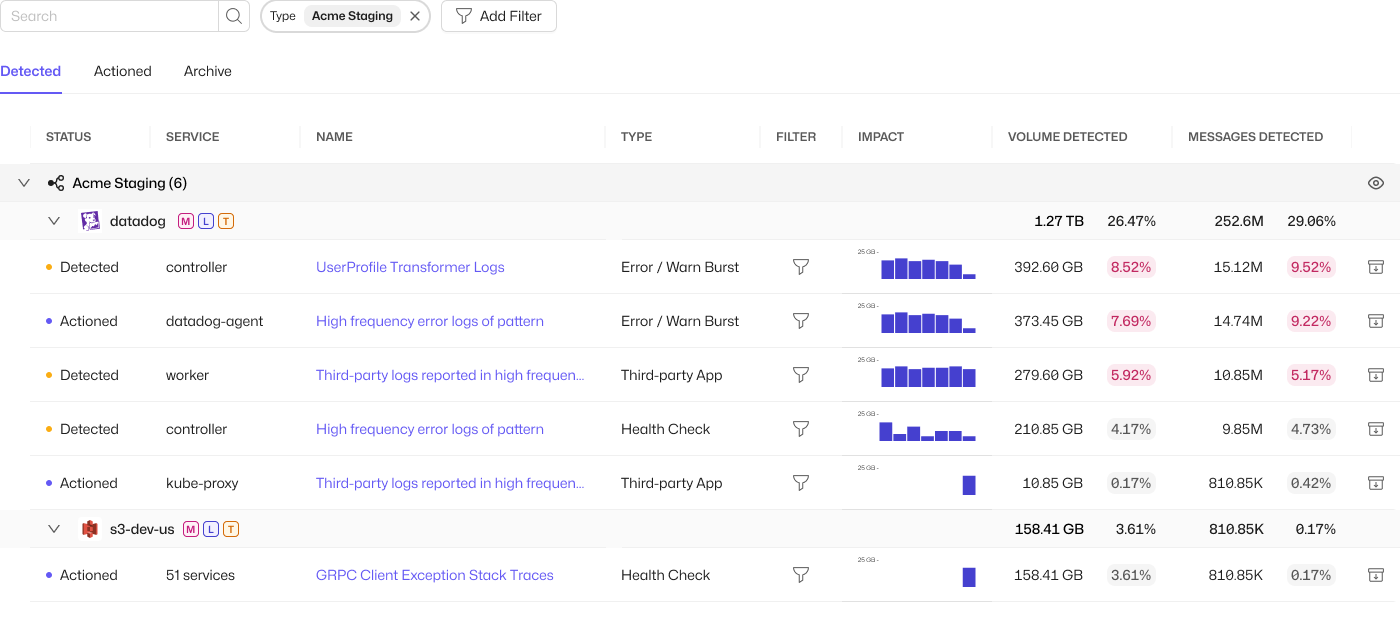
The engineer isn't hunting through rules; they're reviewing a recommendation the system already produced and deciding yes or no. As your applications change, Sawmills keeps surfacing what's new. That's not manual upkeep. It's the AI doing the analysis in the open and leaving the decision with the people who own the services. And most importantly, implementation is a click of a button or a message in Slack or Teams to the Sawmills agent.
Empowerment for engineers, guardrails for DevOps
That same ownership split is why we built in a collaborative management approach between engineers and DevOps.
If engineers own the services and DevOps owns the problem, the pipeline has to serve both without letting either make invisible changes to the other's world. So Sawmills lets engineers serve themselves, adjust what their own services emit, test a change against live data before it ships, and see the before-and-after of every processor in real time, while DevOps keeps the guardrails: governance in the center, autonomy at the edges. DevOps gets the cost and reliability controls they're accountable for; engineers keep visibility and control over the services they own. The pipeline becomes a bridge between the two teams rather than a black box one of them operates on the other.
Here's an example of what that looks like in practice, end to end. Sawmills detects that a service has started emitting a flood of repetitive debug logs overnight, a noisy pattern quietly running up the observability bill. Instead of silently dropping it, Sawmills surfaces the insight: it flags the issue, shows the exact log lines responsible, and recommends a fix, like sampling the pattern down or filtering it.
The engineer who owns that service gets pinged in Slack. They can see what Sawmills found, inspect the actual data, and act right there by applying the recommended filter, adjusting what's being captured, or deciding the logs matter and leaving them alone. No ticket, no context switch, no waiting on another team.
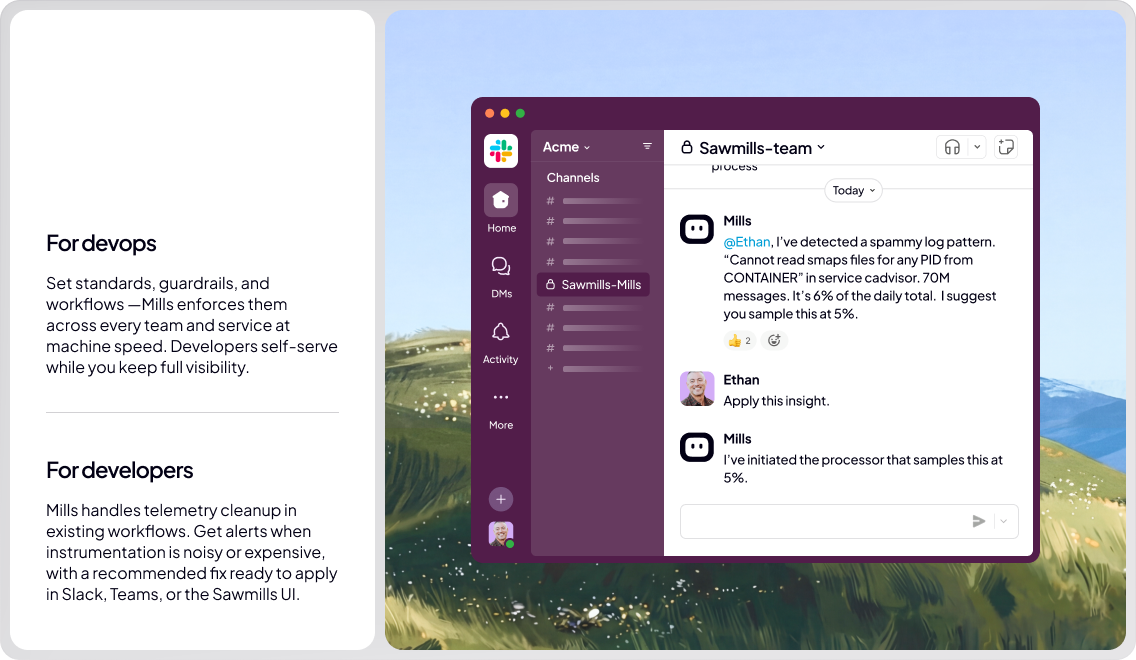
DevOps isn't in the dark. The change is theirs to see, recorded with who made it and why, and it lands inside the guardrails they've already set for which patterns can be touched and what's off-limits. If the applied fix ever crosses a line DevOps cares about, they can step in and override or roll it back. They keep the cost and reliability controls they're accountable for without chasing the engineer or micromanaging the change.
That's the difference: the issue gets found, fixed, and recorded, with the person who owns the service making the call and the team that owns the budget keeping oversight. Both teams move together, in the open, instead of one quietly acting on the other.
That's why we settled on this model. It's not that automation is bad, it's that moving fast only works when the team that owns the problem and the team that owns the services move in lock step. A pipeline should help them do that together.
Standards and inspectability, by design
Building on the OpenTelemetry Collector is a deliberate choice, not a constraint we settled for. It means your pipeline speaks an open, vendor-neutral standard rather than a proprietary engine. Less lock-in, a transform model your engineers can actually inspect, and a rich, growing library of processors for filtering, masking and PII redaction, metric cardinality reduction, log-to-metric conversion, enrichment, and more. Every transform is explicit and every step is inspectable. When an auditor asks what happens to sensitive fields, or an engineer wants to know why a value changed, "look, here's precisely what the pipeline did" is a better answer than "the engine handled it."
There's a real philosophical fork here: a proprietary engine you trust to be smart, versus an open, standards-based pipeline you can see through. We built Sawmills for teams who want the second.
Lower cost. Little disruption.
Start with cost, because it's the primary reason anyone looks at a telemetry pipeline at all. Keeping humans in the loop doesn't mean leaving savings on the table; it means the savings hold up. Sawmills has proven that our model generates massive savings while helping to bridge engineering and DevOps teams.
BigPanda cut observability costs 63% and ingest 93% with Sawmills. BigID took log costs down 81% and ingest 89%, going from 111TB to 12TB a day. HiBob reduced ingest 43% and stopped overrunning its bill entirely. Those are decisions their teams made and can see, not reductions a model applied on their behalf. The headline percentage isn't the hard part; getting deep cuts without quietly dropping the data you needed is, and that's exactly what a human-in-the-loop model protects.
Then there's "no rip and replace," which Grepr frames as their advantage. It's ours too. Sawmills is built on OpenTelemetry and sits in front of the tools you already run; your agents, dashboards, and alerts stay where they are, and we work alongside them rather than replacing anything. The choice was never disruption versus convenience. It's whether, once you're in, the system keeps you in control of what happens to your data or asks you to trust that it guessed right.
How we think about Sawmills vs Grepr
Grepr's post closes with a feature table. We'll borrow the format, but we'll frame each row around what we think it means for the team running the system.
What you keep on the way down
Both Grepr and Sawmills will lower your observability bill. The question is what you want to hold onto on the way down.
If you want a proprietary engine that automatically decides what to keep, Grepr makes a case for that model. If you want your engineers to keep control and visibility, AI insights in the stream rather than a black box around it, explicit and inspectable transforms, and developer empowerment under DevOps governance, that's the bet Sawmills makes.
See it on your own data
If this is the kind of control and visibility you want for your team, the fastest way to judge it is to watch it happen to your own telemetry, not ours. Book a 30-minute walkthrough.


